


🤖 Tech Talk: Self-learning LLMs are here, but they aren't reasoning (yet)
Plus: Employers double down on GenAI talent; OpenAI unit gets $200 mn AI deal from Pentagon; AI tool of the week: Perplexity Labs to turn messy user feedback into actionable insights, and more.

Dear reader,
Researchers at the Massachusetts Institute of Technology (MIT) have introduced a Self-Adapting Language Models (SEAL) framework, marking a significant leap in large language model (LLM) research. Unlike traditional models that require manual fine-tuning or prompt engineering, SEAL allows models to adapt autonomously by generating their own training data and optimization directives.
Using reinforcement learning (RL) and supervised fine-tuning (SFT), SEAL evaluates the quality of its own "self-edits"—task-specific examples and learning instructions—then updates its own weights accordingly. This persistent adaptation capability makes SEAL one of the most autonomous LLM frameworks to date.
RL and SFT are two ways language models learn. In RL, the model learns by trial and error—trying different answers and getting rewarded for better ones (e.g., saying “New Delhi” instead of “Mumbai” for India's capital). SFT is more direct: the model is shown questions with correct answers and learns by example. SEAL combines both—generating its own training examples, using RL to pick the most useful ones, and applying SFT to update its learning.

SEAL’s codebase, openly available via GitHub, includes full documentation, scripts, and SLURM support for scaling on clusters. AI models include Simple Linux Utility for Resource Management (SLURM) support to enable the code to run efficiently on clusters, automatically managing resources like graphics processing units (GPUs) and scheduling large training tasks. For compute-heavy models like SEAL, SLURM enables scalable, parallel processing across multiple machines, streamlining training and experimentation.
SEAL isn't alone
SEAL isn’t the first AI model to learn autonomously, and in fact, it builds on a longer lineage of systems that aim for self-improvement. For instance, models like AlphaGo and AlphaZero (from DeepMind before it was acquired by Google's parent, Alphabet) taught themselves to master Go, chess, and shogi through self-play—zero prior human examples.
Automated machine learning, or AutoML, pioneered by Google and others, already enables models to search architectures (e.g., NASNet, EfficientNet via Neural Architecture Search), tune hyperparameters automatically, and select and compose pipelines based on task and dataset. This autonomy primarily operates during training or configuration, not at inference (when a trained AI model makes predictions or generates outputs based on new input) time.
Reinforcement Learning from Human Feedback (RLHF) lets LLMs improve their outputs based on human preferences, but it's increasingly being bootstrapped into AI feedback (e.g., models ranking or critiquing other models). Meta-learning models (e.g., MAML) "learn to learn" frameworks optimize for quick adaptation to new tasks, which is conceptually similar to SEAL’s few-shot self-finetuning.
So what’s different about SEAL? This MIT LLM framework integrates instruction generation, RL selection, and weight updating within a single unified loop. It applies this not in games or narrow tasks, but in language and reasoning domains, which are traditionally less structured and more error-prone.
On a simplified subset of the ARC benchmark, SEAL achieves a 72.5% success rate, significantly outperforming both in-context learning (0%) and test-time training with untrained self-edits (20%). This demonstrates the framework’s ability to learn how to configure augmentations and training strategies autonomously, enabling robust generalization from limited demonstrations.

Yet, reasoning poses a challenge
When we talk about reasoning models, most of the current improvements appear to be getting better at producing the "right-looking" answer without understanding why it's right, which is at the core of the reasoning debate. Reasoning requires models not only to improve output quality, but also to detect and correct their own logic. Studies show that even advanced models often fail at self-evaluation, frequently reinforcing flawed reasoning when left unchecked.
SEAL improves performance via reward-guided updates, but these are still based on external task scores—not internal logical coherence. Moreover, SEAL is vulnerable to catastrophic forgetting, where new edits overwrite older knowledge, and it lacks mechanisms for preserving long-term consistency.
Critics argue that such systems still operate largely as sophisticated pattern matchers. While they may produce fluent, multi-step responses, they often lack abstract rule application or consistent generalization—hallmarks of genuine reasoning. SEAL’s black-box weight updates also make it difficult to trace whether improvements stem from better reasoning or better mimicry.
What SEAL can do:
Upon receiving a new task, the model crafts “self-edits”—examples for fine-tuning along with optimization instructions.
After these self-edits, the model goes through supervised fine-tuning (SFT) to permanently incorporate improvements.
A reinforcement learning (RL) loop evaluates task performance and refines which self-edits are effective.
SEAL integrates adaptation within the model itself, eliminating reliance on auxiliary modules or toolkits.
It’s a step toward autonomous, evolving AI—models that continuously adapt to fresh tasks or data without human oversight.
But can it reason?
LLMs still struggle to detect and correct their own reasoning flaws, often introducing entirely new errors during attempts at self-correction. Hence, if a model can’t reliably identify mistakes, adapting itself effectively is questionable.
Techniques like chain-of-thought (COT) prompting can produce fluent, seemingly logical steps. But critics argue that models often rely on pattern matching and memorization, and not true, abstract reasoning.
Empirical tests suggest LLMs struggle with generalizable reasoning, especially in contexts that diverge from their training distribution .
Self-improvement systems that use generated consensus (like SEALONG) may reinforce shared errors—if models agree on an incorrect path, it becomes more deeply embedded.
You may read the paper, 'Self-Adapting Language Models' here.
Employers double down on GenAI talent, led by tech and analytics
Indian employers are increasingly on the lookout for candidates skilled in Generative AI (GenAI). According to data from job portal Indeed as of May, about 1.5% of job postings in India explicitly mention GenAI—more than twice the share seen a year ago. While the bulk of these opportunities lie in the tech sector, demand is rapidly broadening.
GenAI is now referenced in 12.5% of data analytics job descriptions, followed by software development (3.6%) and scientific research (3.1%). Even office-based roles are seeing GenAI creep in, with 1.1% of marketing and 0.9% of management listings mentioning it.

Regionally, Karnataka leads with 2.4% of job postings mentioning GenAI, narrowly ahead of Telangana at 2.3%. Maharashtra, despite having the highest overall job volume and second-largest share of GenAI-related roles, sees just 1% of listings mention the technology.
In my June 13 newsletter, I had pointed out that India leads global GenAI adoption with 1.3 million enrollments in 2024, yet ranks poorly at 89th out of 109 countries in the latest Coursera's Global Skills Report, and 46th on its newly-launched AI Maturity Index. However, the QS Future Skills Index ranked India 25th globally as a "future skills contender". India scored exceptionally well in "future of work" metrics (99.1), ranking second only to the US (100).
Despite their different methodologies, both rankings underscore that India has the world's youngest workforce with strong momentum in tech upskilling, supported by government initiatives like Skills India and a robust startup ecosystem that's building future workforce readiness. You may read more about this here.
OpenAI unit gets $200 millionn AI deal from Pentagon. But all’s not well with OpenAI and Microsoft
The US Department of Defense has awarded a $200 million contract to OpenAI Public Sector LLC, a subsidiary of OpenAI, under a fixed-amount prototype agreement that tasks the company with developing cutting-edge AI prototypes—often referred to as “frontier AI”—to support both combat operations and broader defense enterprise functions. The work will focus on enhancing national security capabilities through advanced AI systems, spanning applications in battlefield decision-making, logistics, threat detection, and digital operations.
Strained partnership
The partnership between OpenAI and Microsoft is at a “boiling point”, reported The Wall Street Journal, with the AI leader considering filing antitrust complaints after disputes over compute access, IP rights, and company restructuring. The latest argument comes over OpenAI’s $3B acquisition of Windsurf, with the company wanting to withhold the IP due to Microsoft’s rival GitHub Copilot. OpenAI is reportedly considering the “nuclear option” of accusing Microsoft of anticompetitive behaviour and pushing for a federal review of the partnership. OpenAI has been seeking to reduce its dependency on Microsoft, partnering with rival Google on cloud compute last week. You may read the full story here.
The context
Microsoft, which has invested more than $10 billion in OpenAI, uses the startup's GPT-4 to power Microsoft Copilot, among other things. But this strategy appears to have demoralized its in-house teams that use artificial intelligence tools to power the company’s products and services. In March, Business Insider reported that Microsoft's partnership with OpenAI had affected the morale of the tech company’s AI platform team, which is central to homegrown AI advances and development. OpenAI’s organisation structure could pose another problem for Microsoft. You may read more about this at 'Why Microsoft is cosying up with OpenAI rivals'.
AI Unlocked
by AI&Beyond, with Jaspreet Bindra and Anuj Magazine
This week, we’re unlocking Perplexity Labs, an AI-powered tool that can turn messy user feedback into clear, actionable insights.
The problem with fragmented user reviews/feedback
Product teams regularly face a challenge: User feedback is scattered across X posts, online reviews, and forums, often overwhelming and hard to synthesize. Manually sorting through this data to pinpoint recurring issues like poor output quality, complex interfaces, or slow performance takes hours, delaying critical improvements. This fragmented process risks missing key pain points, leading to stagnant user experiences and lost trust.
Perplexity Labs tackles this by automating deep web research, aggregating insights, and visualizing trends in minutes, empowering teams to act swiftly and effectively.
How to access: www.perplexity.ai (Pro subscription, $20/month)
Perplexity Labs can help you:
- Aggregate feedback: Pull insights from X, reviews, and web sources into one report.
- Visualize trends: Create dashboards to spotlight pain points and themes.
- Drive action: Deliver tailored recommendations to enhance user experience.
Example:
Scenario: You’re a product manager building an AI image generation app. Here’s how Perplexity Labs help you identify gaps in this segment.
Prompt:
- Create a comprehensive report analyzing user feedback for AI image generation tools by summarizing pain points and recurring themes from X posts, online reviews, and relevant web sources. Focus on identifying common issues such as low-quality outputs, complex or ineffective prompt requirements, slow processing times, lack of customization options, or challenges with user trust and engagement. Organize the findings into a clear, structured report with the following components:
- Summary of Pain Points
- Recurring Themes Dashboard
- Actionable Recommendations
- Assets: Ensure all generated content, such as charts, images, and datasets, is organized in the Assets tab for easy access and download.
- Use deep web browsing to gather real-time data from X posts and online reviews, and employ code execution to create the dashboard. The report should be professional, concise, and designed to assist product managers in prioritizing improvements for AI image generation tools.
Steps to use in Perplexity Labs:
- Access Labs: Log into Perplexity Pro, select Labs mode.
- Input prompt: Paste the prompt.
- Monitor progress: Labs browses sources and generates a report/dashboard in about 10 minutes.
- Review outputs: Explore report, recommendations, and Assets tab for charts.
- Refine: Use prompts like, “Update dashboard with a heatmap for issue trends”.
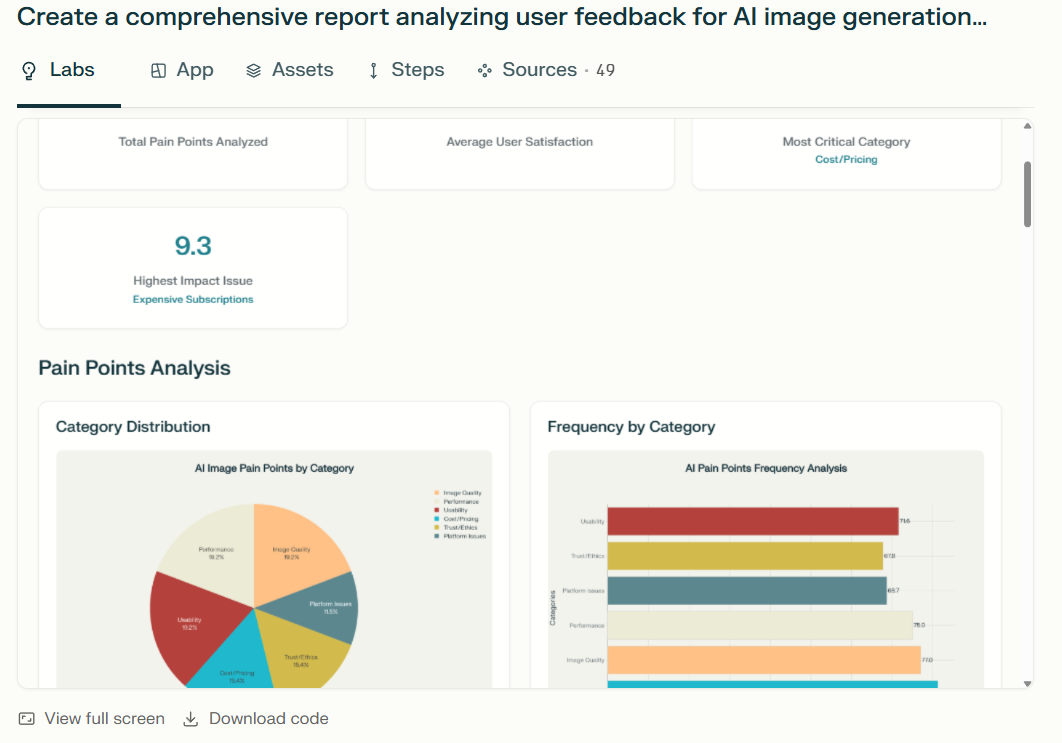
What makes Perplexity Labs special?
- Integrated workflow: Combines research, analysis, and visualization seamlessly.
- Asset hub: Organizes charts and data in the Assets tab for easy access.
- Pro efficiency: Delivers complex insights quickly, exclusive to Pro users.
Note: The tools and analysis featured in this section demonstrated clear value based on our internal testing. Our recommendations are entirely independent and not influenced by the tool creators.
Cybercriminals target India’s schools and colleges with stealthy malware
India’s education and research sector has become the country’s top target for cyberattacks, facing an average of 8,487 weekly attacks per organization over the past six months—nearly double the global average of 4,368, according to a report by Check Point Software Technologies. Other heavily targeted sectors in India include healthcare (5,401 attacks), government/military (4,808), and consulting (4,204).

The sharp spike in attacks on educational institutions stems from their rapid digital shift to hybrid learning, widespread use of personal devices, and limited cybersecurity resources, making them soft targets for cybercriminals. A staggering 74% of Indian organizations report vulnerabilities related to information disclosure, while other common threats include remote code execution (62%), authentication bypass (50%), and denial of service (30%).
Targeting LLMs
Kaspersky researchers have uncovered a new malicious campaign spreading a Trojan through a fake DeepSeek-R1 LLM app for PCs. The malware is distributed via a phishing site that mimics the official DeepSeek homepage and is promoted through Google Ads targeting users searching for “deepseek r1”. Once on the spoofed site, Windows users were prompted to download tools like Ollama or LM Studio to run DeepSeek offline. The installer bundled legitimate tools with malware that bypassed Windows Defender using a special algorithm.
Games Gen Z plays
Kaspersky also detected over 19 million attempts to download malicious or unwanted files disguised as popular Gen Z games between 1 April 2024 and 31 March this year. Grand Theft Auto (GTA), Minecraft, and Call of Duty were among the most exploited games. In India, the report recorded 4,053 unique users targeted by malicious files disguised as popular Gen Z games.
The fact is that Gen Z plays more than any other generation, and outpaces Millennials and Gen X in gaming-related spending. Further,instead of sticking to a few favourites, Gen Z jumps between numerous titles, chasing viral trends and new experiences. Kaspersky has launched 'Case 404', an interactive cybersecurity game, to teach Gen Z how to recognize threats and protect their digital worlds while playing.
You may read more about how 'AI is rewriting the cyber playbook; what should we do? '.
You may also want to read
AI may cause mass unemployment, says Geoffrey Hinton
Musk’s xAI burns through $1 billion a month as costs pile up
Sam Altman says Meta offered $100 million bonuses to OpenAI employees
Opinion: AI models aren’t copycats but learners just like us
Hope you folks have a great weekend, and your feedback will be much appreciated — just reply to this mail, and I’ll respond.
Edited by Feroze Jamal. Produced by Shashwat Mohanty.