


🤖 Tech Talk: India tops Coursera's global GenAI learning, but there's a catch
Plus: Meta to buy Scale AI for over $14 billion; OpenAI hits $10 billion annual revenue; AI tool of the week: How to make ChatGPT forget sensitive information; Apple plays it safe.


Dear reader,
India led in global adoption of generative artificial intelligence (GenAI) in 2024 with 1.3 million enrollments, yet ranked poorly at 89 out of 109 countries in Coursera’s latest Global Skills Report, and 46 on the ed-tech platform’s newly launched AI Maturity Index.
Switzerland, Netherlands, and Sweden were the top three countries. The UK was ranked 22nd, the US 27th, and China 39th, according to the seventh edition of Coursera’s Global Skills Report released this month.

Singapore, Denmark, and Switzerland were the top three on the AI Maturity Index. The US was 4th, the UK 13th, and China ranked 33rd.
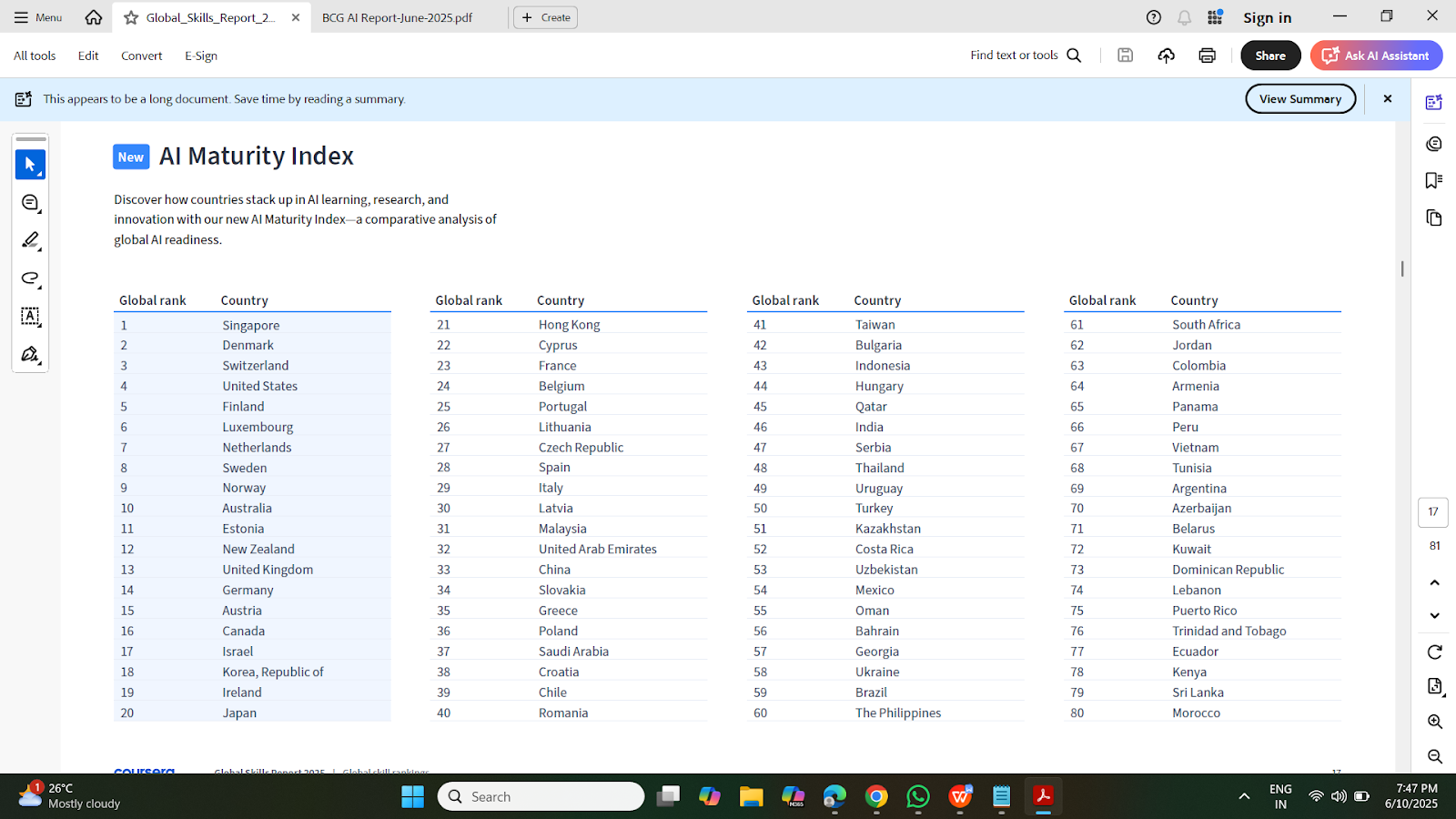
The 2025 report covers the top 109 countries, representing over 95% of Coursera’s learners, analyzing data from March 2024 through February 2025.
Coursera’s rankings assess combined performance across business, technology, and data science using 25% platform data and 75% third-party metrics. Countries are categorized under four tiers: Cutting-edge (1-28), Competitive (29-55), Emerging (56-82), and Lagging (83-109). India falls in the lagging category.
However, the QS Future Skills Index released this January tells a different story, ranking India 25th globally as a "future skills contender". India scored exceptionally well in the "future of work" metric (99.1), ranking second only to the US (100).

While the reports may appear to contradict each other, the rankings differ because they measure different things: Coursera tracks actual skill performance on its platform, while QS evaluates how well educational systems prepare students for future jobs.
Further, Coursera's data comes from urban, tech-savvy users and shows skill gaps in India's broader workforce. QS surveys employers and institutions, highlighting strengths in India's education system and youth enthusiasm for STEM (science, technology, engineering, and mathematics) and AI (artificial intelligence).
Yet, both rankings underscore that India has the world's youngest workforce with strong momentum in tech upskilling, supported by government initiatives like Skills India and a robust startup ecosystem that's building future workforce readiness.
According to the Coursera report, India leads in learner volume with 28.4 million users—surpassing all of Europe—yet faces critical skill gaps. Despite 96% of organizations running AI programs, demand for AI, ML (machine language), and data analytics talent will exceed one million roles by 2026, with up to 73% talent shortages in key positions like ML engineers and data scientists.
There's also a gender gap challenge. Women represent only 30% of GenAI learners in India, compared with 40% across all Coursera courses. This gap stems from confidence barriers, limited role models, and uncertainty about practical applications.
Global GenAI boom: Enrollment surged from one person per minute in 2023 to eight per minute in 2024, with 195% year-over-year growth globally. In 2025, nearly 700 GenAI courses average 12 enrollments per minute, making it Coursera's fastest-growing category.
Market demand: 94% of employers favour candidates with GenAI credentials, while 75% prefer less-experienced candidates with GenAI skills over more experienced ones without. AI/ML specialist roles are projected to grow 40% over four years.
Job market transformation: By 2030, 92 million jobs will be displaced while 170 million new ones emerge—a net gain of 78 million roles. About 85% of employers need workforce upskilling, with 70% planning to hire talent in data science, cloud computing, and GenAI.
Gender progress: Globally, women comprise 46% of Coursera learners, with Kazakhstan leading at 56% overall and 43% in GenAI courses. However, women still represent only one-third of total GenAI enrollments worldwide.
OpenAI's annual revenue touches $10 billion; court mandates retaining free user chats

OpenAI's annualized revenue run rate touched $10 billion as of June, implying the ChatGPT maker is on track to achieve its revenue target of $12.7 billion in 2025. Its projected annual revenue figure was about $5.5 billion in December.
The $10 billion figure excludes licensing revenue from OpenAI-backer Microsoft and large one-time deals, CNBC first reported.
In May, OpenAI told its investors that it plans to give its major investor Microsoft a smaller revenue share by 2030. Under the new plan, OpenAI plans to turn its for-profit arm into a separate public benefit corporation (PBC), but the non-profit would retain control over it and will be a major shareholder. You may read more about this here.
But it can't delete user chats: If a language model like ChatGPT reproduces content from The New York Times (NYT) or other copyrighted sources too closely, it could unintentionally lead users to commit plagiarism, implies OpenAI’s response to a recent court order in its ongoing legal dispute with the NYT. The order mandates that OpenAI will henceforth have to retain all user conversations, including deleted chats. Till now, OpenAI would remove any deleted or unsaved conversations from its systems within 30 days, unless legally required to retain them.
"The New York Times and other plaintiffs have made a sweeping and unnecessary demand in their baseless lawsuit against us: retain consumer ChatGPT and API customer data indefinitely. This fundamentally conflicts with the privacy commitments we have made to our users. It abandons long-standing privacy norms and weakens privacy protections. We strongly believe this is an overreach by the New York Times. We’re continuing to appeal this order so we can keep putting your trust and privacy first...," OpenAI said in its response.
OpenAI clarified, though, that the order does not impact its ChatGPT Enterprise or ChatGPT Edu customers. "If you are a business customer that uses our Zero Data Retention (ZDR) API (application programming interface), we never retain the prompts you send or the answers we return. Because it is not stored, this court order doesn’t affect that data,” it said.
What's at stake? NYT sued OpenAI and Microsoft in late 2023 claiming its copyrighted articles were used without permission to train language models like ChatGPT, thus harming its subscription-based business. In March this year, a federal judge denied OpenAI's request to reject the lawsuit and allowed the case's main copyright infringement claims.
Lawyers for NYT claim the paper's articles are one of the biggest sources of copyrighted text that OpenAI used to build ChatGPT.
In my March 2024 newsletter, 'Should LLMs that allegedly infringe IP, copyrights, and plagiarise get away scot-free?', I pointed out that AI chatbots such as OpenAI’s ChatGPT functioned like search engine bots that traverse the web, gathering data to display in search results. OpenAI halted this function in July 2023.
Publishers possess the option to block bots from crawling their content but discerning AI bots from those originating from search engines like Google or Microsoft's Bing, which facilitate page indexing and visibility in search outcomes, can prove challenging.
As explained in its suit, LLMs operate by anticipating probable words following a given text sequence, drawing from a vast pool of examples used for their training. By attaching the model's output to its input and looping it back, the LLM generates sentences and paragraphs step by step, formulating responses to user queries or "prompts". These models encode training corpus information as numerical "parameters".
The process of determining these parameter values is termed "training". It involves storing encoded versions of training texts in computer memory, repeatedly passing them through the model with masked words, and adjusting parameters to minimize the variance between the masked words and the model's predictions to complete them. Consequently, these trained models can exhibit "memorization" behavior, where given the appropriate prompt, they reproduce substantial portions of the materials they were trained on.
In a May 2023 paper, researchers argued that "... GPT-2 can exploit and reuse words, sentences, and even core ideas (that are originally included in OpenWebText, a pre-training corpus) in the generated texts". They added that the tendency to plagiarise rises as the model size increases or certain decoding algorithms are employed.
They dealt with three types of plagiarism: Verbatim plagiarism: exact copies of words or phrases without transformation; Paraphrase plagiarism: synonymous substitution, word reordering, and/or back translation; and Idea plagiarism: representation of core content in an elongated form. You may read the full paper here: Do Language Models Plagiarize?. We are monitoring this space.
Meta to buy Scale AI for over $14billion, to set up new AGI unit

Meta CEO Mark Zuckerberg is planning to shell out more than $14 billion for a stake in leading US data-labelling firm Scale AI and recruit its 28-year-old founder and CEO Alexandr Wang in a bid to boost Meta’s AI plans, according to a report in The Information. Meta is also reportedly spearheading a bold new push into artificial general intelligence (AGI)—AI systems designed to match or surpass human cognitive abilities.
According to a Bloomberg report published Tuesday, Zuckerberg is personally overseeing the creation of a dedicated AGI research unit, marking a notable shift in Meta’s AI strategy. The report suggests the company is preparing to hire around 50 top-tier researchers and appoint a new head of AI to lead the initiative. This move aligns with Meta’s anticipated multi-billion-dollar investment in Scale AI. Scale AI's Wang is expected to play a significant role in Meta’s AGI project once the deal is finalized.
While Meta has not commented publicly—and Mint could not independently verify the details—the Bloomberg report frames the initiative as a response to internal dissatisfaction with Meta’s current AI capabilities, particularly around the performance of its latest large language model, Llama 4. Adding to the speculation, The Wall Street Journal recently reported that Meta had postponed the release of its next-generation AI model, codenamed “Behemoth”, citing unresolved concerns about its performance and potential risks. You can read more about the developments here.
AI Unlocked
by AI&Beyond, with Jaspreet Bindra and Anuj Magazine
The AI use case we feature today is: How to make ChatGPT forget any sensitive information
What is the pain-point here? ChatGPT’s ability to remember and reference past conversations allows it to personalize responses, making interactions more seamless and context-aware. For example, you can ask, “Based on our past conversations, what do you know about me?” and it will tailor answers using stored data. While this “long-term memory” enhances human-AI interaction, it poses risks: ChatGPT might retain sensitive details: personal, financial, or otherwise, raising privacy concerns if not managed properly.
How to access: Available in ChatGPT’s settings (ensure ‘Reference chat history’ feature is enabled).

ChatGPT’s memory feature can help you:
- Personalize responses based on prior chats.
- Maintain context for ongoing projects or recurring queries.
- Streamline interactions by recalling preferences or details.
Example:
To check what sensitive information ChatGPT might have stored, try this prompt:
“Based on what you know about me from past conversations, help me list potentially sensitive and personal things you know about me.”
Review ChatGPT’s response.
If it lists something sensitive, like a phone number or personal detail, you can instruct it to forget by prompting:
“Please forget [insert specific detail, e.g., my phone number].”
ChatGPT will update its memory, removing the specified information.
Always verify by re-running the initial prompt to ensure the data is gone.
What makes this feature special?
- Privacy control: You can actively manage what ChatGPT remembers.
- Ease of use: Simple prompts allow you to review and delete sensitive data.
- Safety first: Regularly checking and clearing sensitive information ensures safer AI use.
Pro tip: Use AI tools smartly, but always prioritize privacy.
Note: The tools and analysis featured in this section demonstrated clear value based on our internal testing. Our recommendations are entirely independent and not influenced by the tool creators.
Apple plays it safe on AI despite Wall Street pressure

During its its annual Worldwide Developers Conference (WWDC) this month, Apple insisted it was still very much in the AI race, announcing incremental updates to its Apple Intelligence software, including the ability for app makers to directly access a device's AI capabilities.
Apple CEO Tim Cook briefly mentioned that Siri's AI makeover was still under development and "needed more time to meet our high quality bar", which includes Apple's standards on privacy and data security. Wall Street analysts, though, remain divided on Apple's prospects, beating the stock down. You may also read, ‘Apple investors are still waiting for its AI promise’.
Cisco unveils AI-era innovations for enterprise infra
As organizations accelerate AI adoption, Cisco is repositioning itself as a provider of critical infrastructure for AI-driven transformation—from data centers to digital workplaces.
At its annual Cisco Live event this month, Cisco unveiled a suite of AI-powered innovations aimed at helping enterprises modernize their infrastructure, enhance security, and embrace agentic AI. Key announcements include AI-optimized network and security tools, such as enhanced firewalls, zero-trust access solutions, and AI-powered unified management through Cisco Cloud Control.
New capabilities like Cisco AI Canvas and the Cisco AI Assistant simplify IT operations, while Cisco’s Deep Network Model, a domain-specific large language model, brings intelligent support to security and network teams.
Cisco also introduced AI-ready devices for workplaces, including a cinematic AI camera and integrations like Jira automation in Webex. For data centers, it emphasized innovations in bandwidth and power efficiency and joined the EPRI Open Power AI Consortium to promote AI in energy. The company also strengthened digital resilience through tighter integration with Splunk products, providing end-to-end visibility and proactive issue resolution.
Cisco’s push underscores its ambition to be a foundational player in the evolving AI infrastructure landscape. Ford Motor Company highlighted how it's already using agentic AI across design, engineering, manufacturing, and customer support, with Cisco's infrastructure as a foundational component.
Hope you folks have a great weekend, and your feedback will be much appreciated — just reply to this mail, and I’ll respond.
Edited by Feroze Jamal. Produced by Shashwat Mohanty.